Vision Transformer
RoFormer: Enhanced Transformer with Rotary Position Embedding (Paper) (Code) (Ref) (Note&Blog)
[CVPR22] Unsupervised Hierarchical Semantic Segmentation with Multiview Cosegmentation and Clustering Transformers (Paper) (Code) (Issue)
[ICLR25] An Image is Worth More Than 16x16 Patches: Exploring Transformers on Individual Pixels (Paper)
Meta的一篇文章,但还在ICLR的rebuttle。主要观点是用单独的pixel作为token可以将local的归纳偏置降为零。文章类比bag of words,提出set of pixels,并在其上加上必要的positional embeddings后,输入普通的Transformer可以学习特征可以比切割patch的方式表现更好。当然计算量也更大。重要的是,作者提出可以选择性地输入像素,例如上面的一篇文章。由于没有具体的新模型,只是一个普通的研究,这里记录一些自己的笔记。
- ViT的输入不再是以patch的方式,也就是认为patch和使用连续函数进行位置编码都会来带一定程度的归纳偏置。因此改为pixel的方式,并使用可学习的位置编码可以消除由于locality带来的归纳偏置。
- 将输入改为pixel后,输入的方式就变得比较多样。可以是随机的像素输入,也可以是有结构性地输入,还可以是输入重要的像素等等。文章在提到这些问题的时候引用了这篇文章。
- 可学习的位置编码很重要。
- 无监督学习可以快速学到像素之间的想似性和像素之间的结构特征。
- 如果有标注,依然存在对齐的问题。但是否存在一种方式可以先通过像素为本的预训练学习结构特征,再通过微调快速对其多模态特征。
- 例如text images
- 重要的不是学习像素(因为只有255类,相当于26字母),而是学习像素之间的相对关系,只有满足某种关系的像素集合,才能构成图像。对于text
images而言,这种关系需要满足:
- 这种关系应该是像素集合(
)到图像( )之间的映射,即一个像素需要到一个二维坐标,每个坐标需要有一个像素值,但每个像素值不一定需要坐标,即定义域是像素集合的子集 - 能将像素映射到正确的位置从而呈现出人眼可识别的图像
- 被映射到图像中文本区域的像素需要和embedding后的文本特征对应
- 更强的条件:被映射到文本区域的像素需要按照顺序与embedding后的文本对齐
- 继续思考:embedding后的文本实质上对应的是图像上的一块区域
- 是否可以把文本进行二维编码
- 因此需要模型能在预训练时得到图像中各个区域的隐变量表示,而在微调时快速建立其它模态与这些隐变量之间关系
- 这种关系应该是像素集合(
[ECCV22] CoMER: Modeling Coverage for Transformer-based Handwritten Mathematical Expression Recognition (Paper) (Code)
本文主要针对手写数学公式识别任务魔改了ViT,把Coverage Attention引入ViT的特征层,优化Attention Weights,并进行并行解码,在降低过往注意过的区域的同时提高了解码效率。
- Background
- Coverage Attention: handle the problem in translation i.e. over-translation and under-translation, mainly used in RNN, where Coverage Attention can use the past hidden states and forces the model to attend more on unparsed parts in image. Derictly introducing Coverage Attention to ViT will break the parallel decoding of Transformer.
- Motivation
- introduces Coverage Attention into Transformer's attention layer to refine the attention weights in a prefix-sum form without hurting parallel decoding
- Methods
- designs three types of attention refinement methods i.e. self-, cross- and fusion-coverage
Coverage Attention in RNN: for attention map
Multipling
So the attention item
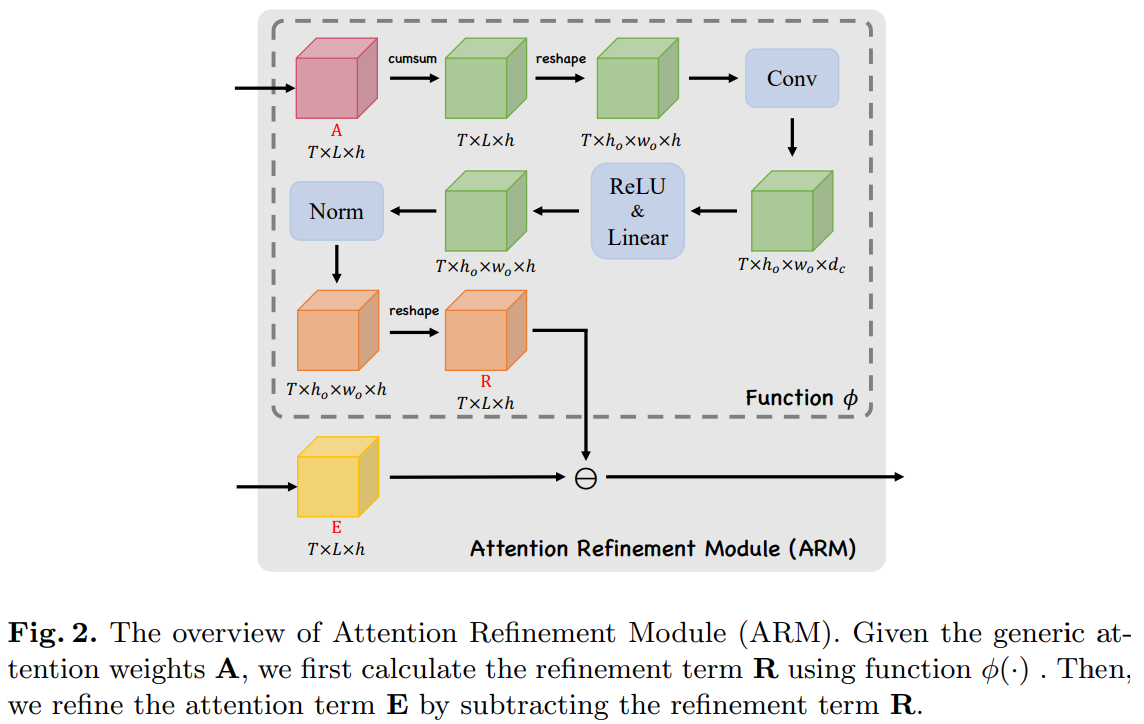
The codes can be found in github
Attention
- In fact, this paper realized an alignment methods: when predicting the label at step
, the refined attention weights attend the next region in image, the region in image aligns the label character at
Multi-modal
[CVPR24] ODM: A Text-Image Further Alignment Pre-training Approach for Scene Text Detection and Spotting (Paper) (Code)
本文主要是实现了文本图像的去形式化,也就是将图片中的文本转化为标准字体,并保持一定的旋转和位置不变,输出在图片上,是一种预训练方式。但是该方式还是使用了标签作为监督。
- Motivation
- in Optical Character Recognition (OCR) tasks, aligning text instances with their corresponding text regions in images poses a challenge, as it requires effective alignment between text (text annotation) and OCR-Text (text in image) rather than a holistic understanding of the overall image content
- transfers diverse styles of text found in images to a uniform style based on the text prompts
- costs in scene text image annotations
- Methods
- ODM model, transfer diverse form into plain form
- label generation, to allow large amount of unlabeled data to participate in pretraining
This is a framework for pre-training, so the encoder and decoder can be any model that is suitable for spotting and detection tasks. The connection between image encoder and text encoder is a cross attention mechanism. The delicately designed part is losses.
- binary segementation loss: for every pixel, calculate binary
corss-entropy loss
- OCR-LPIPS loss: aims to constrain the features, the output binary
and ground truth images are inputed to a well trained detector (e.g.
UNet-VGG with
layers), and then calculate the sum of layer loss - contrastive loss: maps texts and images into the same semantic
space, calculate loss
- total loss:
[CVPR24] Multi-modal In-Context Learning Makes an Ego-evolving Scene Text Recognizer (Paper) (Code)
- Motivations
- difficult to transfer to different domain for STR (such as font sdiversity, shape deformations)
- fine-tuning is computationally intensive and requires multiple model copies for various scenarios
- LLMs with in-context learning fail as the insufficient incorporation of contextual information form diverse samples in the training stage (?)
- In summary: STR models needs fine-tuning to satisfy new scenorios which costs too much. So this paper wants to borrow the ICL in LLM to decrease the costs
- Methods
- train with context-rich scene text sequences (sequences are generated by in-context training strategy)
- regular size model is enough
- Questions
- what is "context-rich", how to depict "rich"
- Multi-modal in In-context learning, training-free
- LLMs can quickly adapt to new tasks with just a few examples (treat these inputs as prompt), this phenomenon is a new learning paradigm termed "In-Context Learning", which means "The label is the input itself". But it's difficult to transfer the learning paradigm to VLMs
Model Architecture
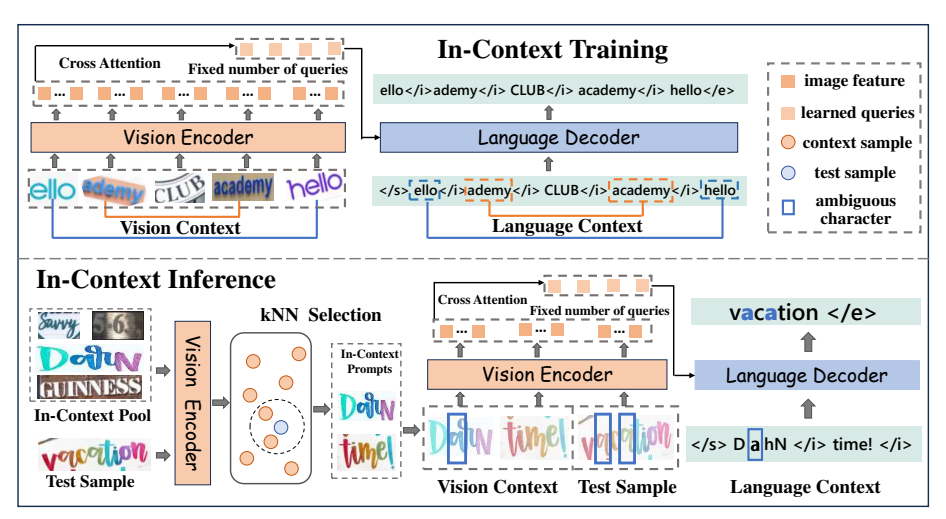
- Model trained in the standard auto-regressive paradigm to learn fundamental STR ability
- In-Context training, learn to understand the connection among different samples
- inference, fetches in-context prompts based on visual similarity
Training Strategy
- Train with original training set
- Generate splited and transformed samples and then concatenate them in a sequence form. Train with these sequences.
Inference
Inference needs to maintain an In-Context Pool, where the k-NN seletion strategy will be conducted. k-NN will select top-K similar samples in latent space to form the prompts
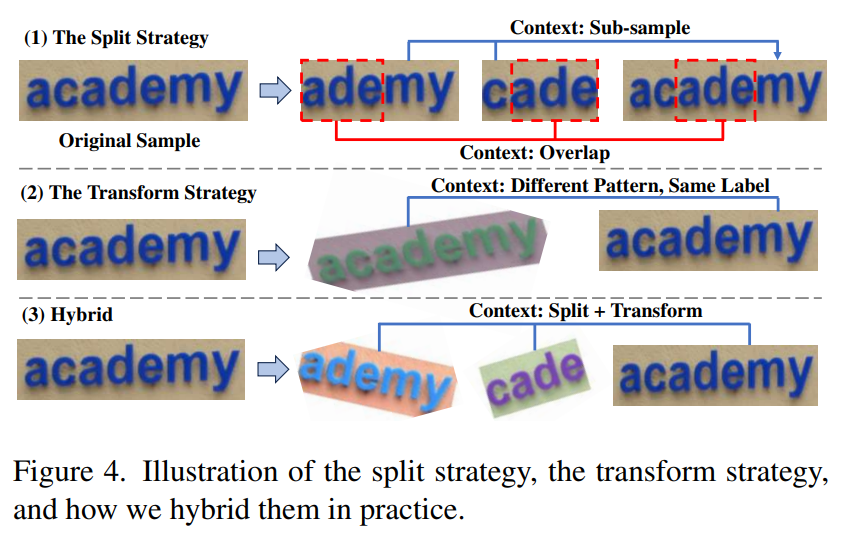
Attention
- The split phase faces the difficulty of alignment, especially for art texts, which can't be splited by a single rectangle (so what about a deformable shape?)
- Inference should maintain an In-Context pool
Distangle Representions
[CVPR24] Choose What You Need: Disentangled Representation Learning for Scene Text Recognition Removal and Editing (Paper)
这篇文章主要是使用了额外的数据集用于提取解耦特征,从数据角度解决特征耦合的问题。
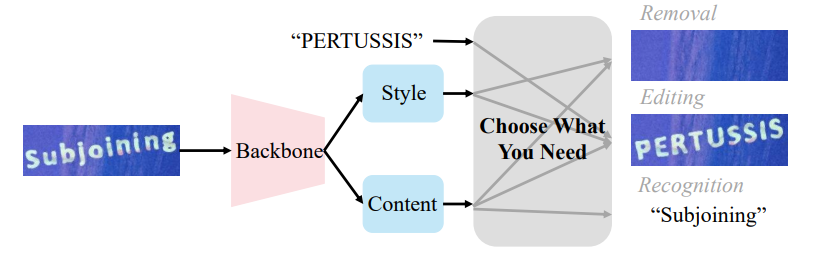
- Motivations
- previous representation learning methods use tightly coupled features for all tasks, resulting in sub-optimal performance
- disentangling these two types (style feature and context feature) of features for improved adaptability in better addressing various downstream tasks
- Methods
- Dataset: we synthesize a dataset of image pairs with identical style but different content, the dataset generator is SynthTIGER
- Losses: content features are supervised by a text recognition loss, while an alignment loss aligns the style features in the image pairs
To illustrate the drawbacks of using tightly coupled features.
- STR with segementation preprocessing
- SIGA
- CCD
- Deformable CNN use a learnable bias in convolution block to represent deformations
The total model is divided into two part, one for generation and the other for recognition. Both parts use MSA to extract features but with different losses. The gradients in context part are blocked to realize decouple target. For multiply layer, model uses gated strategy to fuse multi-layer features.
Attention
- This model divides style and context fetures with the SAME lengths, which may constrain the ability to represent background information, because the background is assumed more complex than texts.