Prob-6 受限最短路径长度问题:给定一无向图G=(V, E, A,
B),A(e)表示边e的长度,B(v)表示顶点v的花费,计算小明从顶点s到顶点d的最短路径长度,满足以下限制,初始时小明随身携带M元钱,每经过一个顶点v,须交B(v)的过路费,若身上有大于B(v)的钱则可以通过,否则不可以通过。求顶点s到顶点d的最短路径
// 用来记录当前路径上的最小容量,用于加流量操作 int a[MAX_V]; // 记录下标点的边编号,pair 对应 G[x1][x2],x1 是描述哪个入度点,x2 是描述 x1 点的第 x2 条边 unordered_map<int, pair<int, int>> pre; voidbfs(int s, int t){ // a 初始化成 0,也可以判断是否已经被染色,从而剪枝情况 memset(a, 0, sizeof(a)); // 使用队列,保存处理节点 queue<int> que; que.push(s); // 每个节点所流过的流量设置为 INF 无穷大 // 这样可以起到求最小的作用 a[s] = INF; while (!que.empty()) { int x = que.front(); que.pop(); // 遍历当前节点的所有边 for (int i = 0; i < G[x].size(); ++ i) { Edge& e = G[x][i]; // 如果相连的点没有访问,并且这条边的容量大于 0 if (!a[e.to] && e.cap > 0) { // 记录下一个点的入度边 pre[e.to] = make_pair(x, i); // 计算当前路径的最小容量 a[e.to] = min(a[x], e.cap); que.push(e.to); } } if (a[t]) break; } }
intmax_flow(int s, int t){ // 最大流结果 int ret = 0; while (1) { // 从 S -> T 使用 bfs 查询一条增广路 bfs(s, t); // 如果发现容量最小是 0 ,说明查不到了 if (a[t] == 0) break; int u = t; while (u != s) { // 使用 pre 来获取当前增广路中汇点 T 的入度边下标信息 int p = pre[u].first, edge_index = pre[u].second; // 获取正向边和反向边 Edge& forward_edge = G[p][edge_index]; Edge& reverse_edge = G[forward_edge.to][forward_edge.rev]; // 更新流量 forward_edge.cap -= a[t]; reverse_edge.cap += a[t]; // 逆增广路方向移动游标继续更新 u = reverse_edge.to; } ret += a[t]; } return ret; }
Prob-1
Graph
Topological sorting
Activity on Vertex Network (AOV)
顶点表示活动。当活动的所有前驱节点都完成,该节点才能执行。
拓扑序列 构造如下
从图中选择入度为0的点
输出该顶点,然后从图中删除此顶点的所有出边
重复上述步骤直到所有顶点都输出,拓扑排序完成;否则图中不存在入度为0的点,是有环图,死锁。
Activity on Edge Network (AOE)
边表示活动/权值/时间,顶点表示事件。
事件(顶点)的最早发生时间
即需要所有前驱节点完成,是源点到该节点的最大路径
事件(顶点)的最迟发生时间
事件的所有后继活动的最迟开始时间的最小值
活动(边)的最早发生时间
活动(边)的最迟发生时间 后继事件的最迟发生时间 - 该事件的持续时间(权值)
关键路径:AOE 网中从源点到汇点的最长路径的长度。
关键活动:即关键路径上的活动,它的最早开始时间和最迟开始时间相等。
递推求最早和最迟发生时间:
按拓扑顺序求,最早发生时间从前往后递推,最迟发生时间从后往前递推
Kaha算法 初始状态下,集合 S 装着所有入度为 0 的点,L
是一个空列表。 每次从 S 中取出一个点 u(可以随便取)放入 L, 然后将 u
的所有边 删除。对于边 ,若将该边删除后点 v 的入度变为 0,则将 v 放入 S
中。不断重复以上过程,直到集合 S
为空。检查图中是否存在任何边,如果有,那么这个图一定有环路,否则返回
L,L 中顶点的顺序就是构造拓扑序列的结果。
voiddijkstra(int n, int s){ memset(dis, 0x3f, (n + 1) * sizeof(int)); dis[s] = 0; for (int i = 1; i <= n; i++) { int u = 0, mind = 0x3f3f3f3f; for (int j = 1; j <= n; j++) if (!vis[j] && dis[j] < mind) u = j, mind = dis[j]; vis[u] = true; for (auto ed : e[u]) { int v = ed.v, w = ed.w; if (dis[v] > dis[u] + w) dis[v] = dis[u] + w; } } }









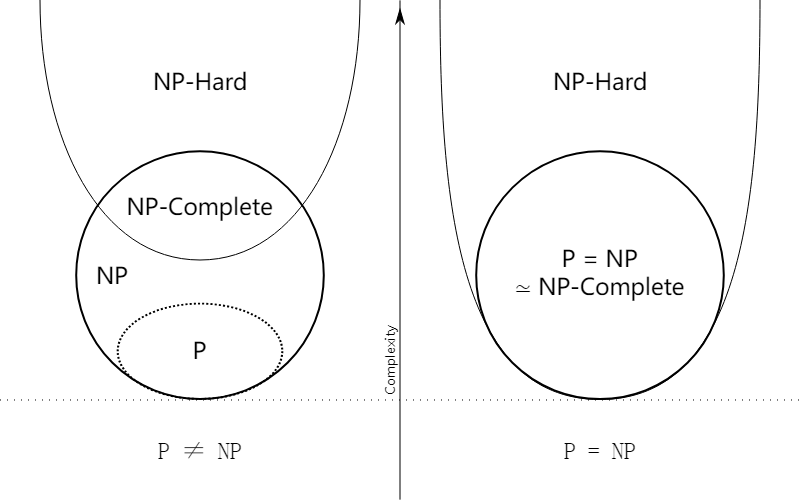
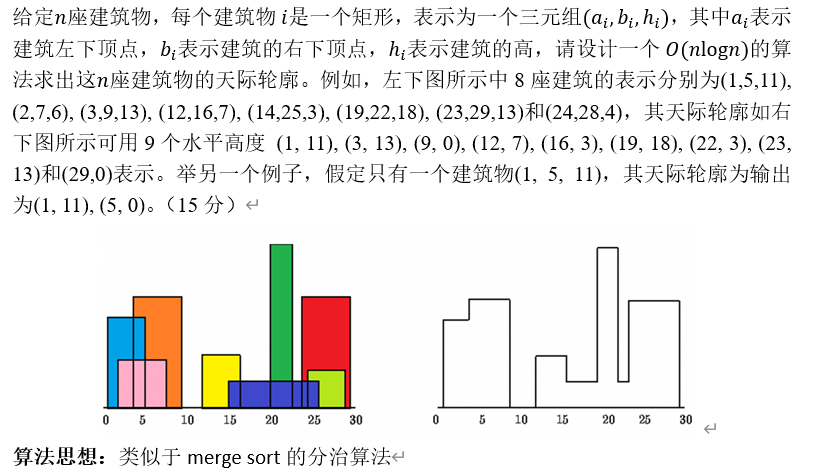

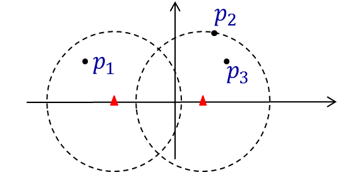

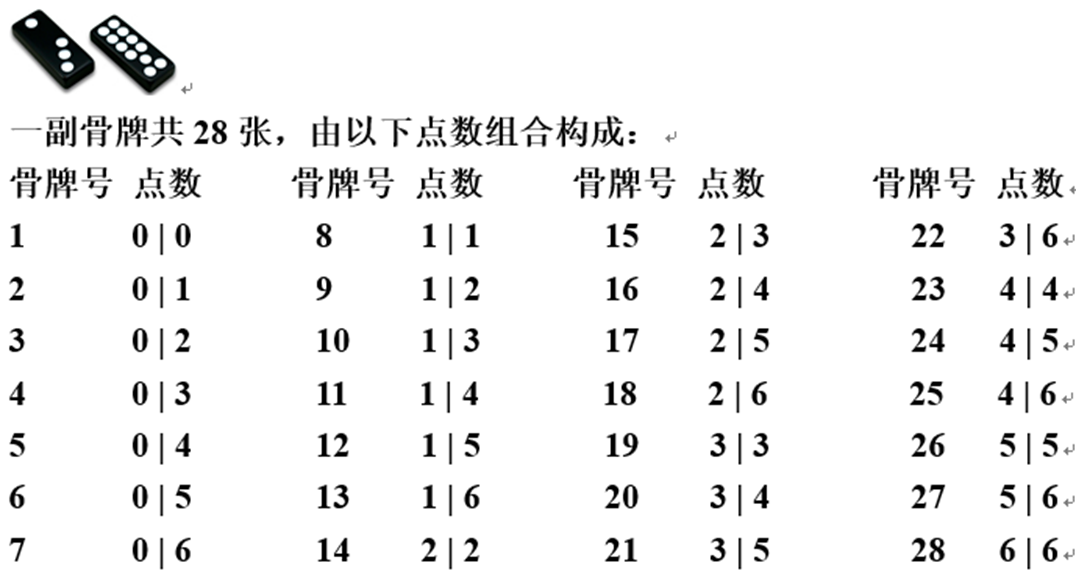
请从给定的点数网格𝒂[𝟏,𝟐,…,𝟕][𝟏,𝟐,…,𝟖]使用搜索算法求出对应 的骨牌号图𝒃[𝟏,𝟐,…,𝟕][𝟏,𝟐,…,𝟖],有可能的话,给出相关剪枝策略。



